作者:央央说去_531 | 来源:互联网 | 2023-07-13 13:45
篇首语:本文由编程笔记#小编为大家整理,主要介绍了漫画趣解Flink实时数仓相关的知识,希望对你有一定的参考价值。
我是Flink,最近我抑郁了~
1 搬橡果的小故事
马上过冬了,我和小伙伴灰灰开始屯年货。
今年劳动了大半年,我们收获了整整一车的橡果。众所周知,我们小松鼠们都喜欢把这些心爱的橡果放到储藏室。
于是今天起了个大早,开始搬运这些橡果。

不一会,灰灰突然对我说想要吃一颗昨天摘的灰色小橡果。
我望了望眼前堆积如山的年货,苦恼的摸了摸脑袋:等我搬到了那颗再给你。
灰灰很不开心,嘴里嘟囔着:为啥昨天不能一摘下来我们就搬呢?
我解释道: 我们每年都是攒够一车才一起搬的呀?
看着一边气鼓鼓的灰灰,我放缓了搬运的速度~
抬头望着高高的橡果堆叹了口气。一边搬运,一边翻找他要的那颗小橡果。。。

今天怕是搬不完了~
2 慢 OR 快?
总结下,在故事中我们遇到了几个小烦恼:
- 每次都是攒了整车橡果才开始搬运,无法
及时拿到想要的灰色小橡果
- 就算我
实时搬运。之后再要其他小橡果,我还是不能快速找到,完全记不住之前拿过哪些?放到了哪里?
借由这个小故事,回归到本文主题。
这些关键词也是企业实时数仓建设中常遇到的一些难点和诉求。
2.1 企业实时数仓建设诉求
大多数企业面临数据源多、结构复杂的问题,为了更好的管理数据和赋能价值,常常会在集团、部门内进行数仓建设。
其中一般初期的数仓开发流程大致如下:
- 获取数据源,进行数据清洗、扩维、加工,最终输出业务指标
- 根据不同业务,重复进行上述流程开发,即
烟囱式开发。

可想而知,随着业务需求的不断增多,这种烟囱式的开发模式会暴露很多问题:
为此大量企业的数据团队开始着手数仓规划,对数据进行分层。
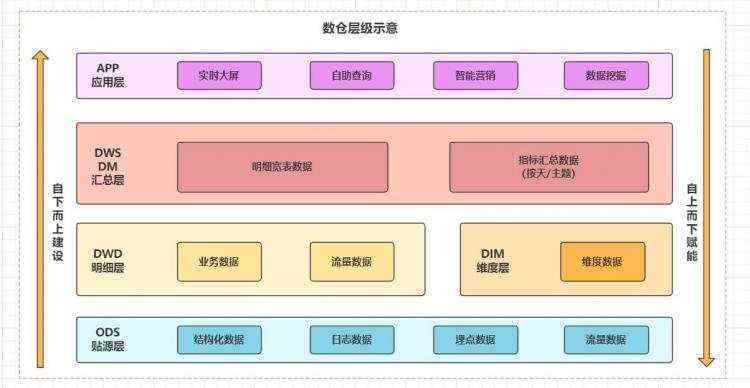
数据规整为层级存储,每层独立加工。整体遵循由下向上建设思想,最大化数据赋能。
- 数据源: 分为
日志数据和业务数据两大类,包括结构化和非结构化数据。
- 数仓类型:根据及时性分为
离线数仓和实时数仓
- 技术栈:
- 采集(Sqoop、Flume、CDC)
- 存储(Hive、Hbase、mysql、Kafka、数据湖)
- 加工(Hive、Spark、Flink)
- OLAP查询(Kylin、Clickhous、ES、Dorisdb)等。
2.2 稳定的离线数仓
早期规划中,在数据实时性要求不高的前提下,基本一开始都会选择建设离线数仓。
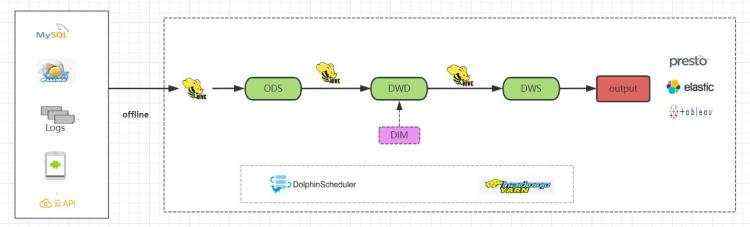
1) 技术实现
- 使用Hive作为数据存储、计算技术栈
- 编写数据同步脚本,抽取数据到Hive的ODS层中
- 在Hive中完成dwd清洗加工、维度建模和dws汇总、主题建模
- 依赖调度工具(dophinScheduler)自动 T+1调度
- olap引擎查询分析、报表展示
2) 优缺点
- 配合调度工具,能够自动化实现T+1的数据采集、加工等全流程处理。技术栈
简单易操作
- Hive存储性能高、适合交互式查询
- 计算速度受Hive自身限制,可能因参数和数据分布等差异造成不同程度的数据
延迟
3) 改良
既然我们知道了Hive的运算速度比较慢,但是又不想放弃其高效的存储和查询功能。
那我们试试换一种计算引擎: Spark。
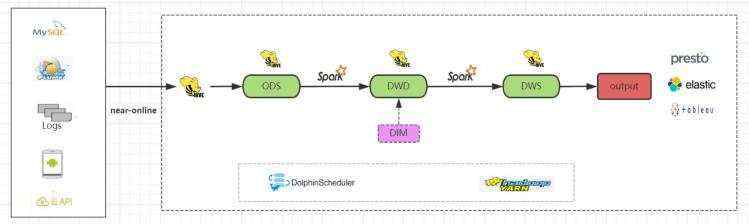
整体流程不变,主要是在ods->dwd->dws层的数据加工由Spark负责。效果是显而易见的,比Hive计算快了不少。
目前两种离线数仓均完美的实现了业务需求。领导第二天一看报表统计,结果皆大欢喜~
现在考虑换一种场景:不想等到第二天才能看到结果,要求实时展示指标,此时需要建设实时数仓。
3 冗余 OR 回溯 ?
既然要求达到实时效果,首先考虑优化加工计算过程。因此需要替换Spark,使用Flink计算引擎。
在技术实现方面,业内常用的实时数仓架构分为两种:Lambda架构和Kappa架构。
3.1 Lambda架构
顾名思义,Lambda架构保留实时、离线两条处理流程,即最终会同时构建实时数仓和离线数仓。
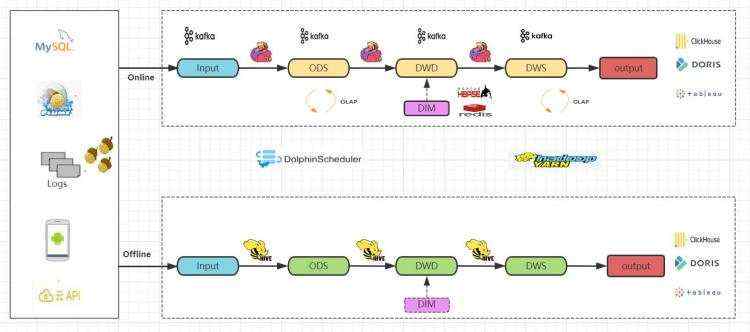
1) 技术实现
- 使用Flink和Kafka、Hive为主要技术栈
- 实时技术流程。通过实时采集程序同步数据到Kafka消息队列
- Flink实时读取Kafka数据,回写到
kafka ods贴源层topic
- Flink实时读取Kafka的ods层数据,进行实时清洗和加工,结果写入到
kafka dwd明细层topic
- 同样的步骤,Flink读取dwd层数据写入到
kafka dws汇总层topic
- 离线技术流程和前面章节一致
- 实时olap引擎查询分析、报表展示
2) 优缺点
- 两套技术流程,全面保障实时性和历史数据完整性
- 同时维护两套技术架构,维护成本高,技术难度大
- 相同数据源处理两次且存储两次,产生大量数据冗余和操作重复
- 容易产生数据不一致问题
3) 改良
针对相同数据源被处理两次这个点,对上面的Lambda架构进行改良。
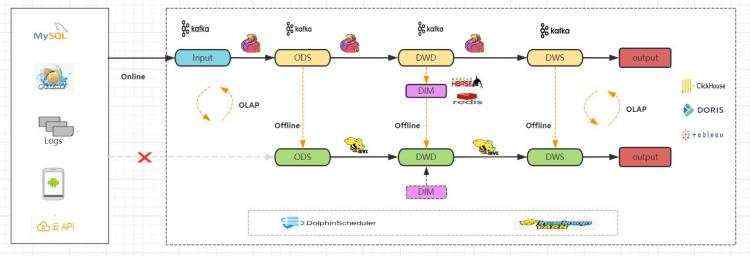
通过将实时技术流的每一层计算结果定时刷新到离线数仓中,数据源读取唯一。大幅减少了数据的重复计算,加快了程序运行时间。
3.2 Kappa架构
为了解决上述模式下数据的冗余存储和计算的问题,同时降低技术架构复杂度,这里介绍另外一种模式: Kappa架构。
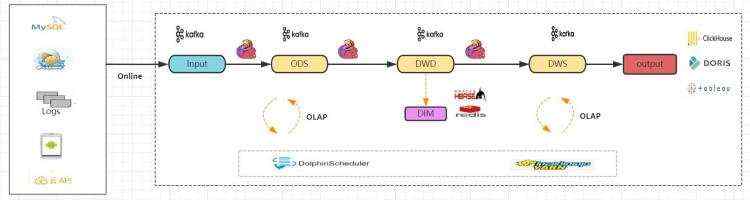
1) 技术实现
- 使用Flink和Kafka为主要技术栈
- 实时技术流和Lambda架构保持一致
- 不再进行离线数仓构建
- 实时olap引擎查询分析、报表展示
2) 优缺点
- 单一实时数仓,强实时性,程序性能高
- 维护成本和技术栈复杂度远远低于Lambda架构
- 源头数据仅作为实时数据流被计算、存储,数据仅被处理一次。
- 数据回溯难。依赖Kafka存储,历史数据会丢失
- olap查询难。Kafka需要引入其他对接工具实现olap查询,Kafka天生不适合olap分析。
总体而言,第一种Lambda架构虽然有诸多缺点,但是具备程序稳健性和数据完整性,因此在企业中用的会比较多。
相反Kappa架构用的比较少。因为Kappa架构仅使用Kafka作为存储组件,需要同时满足数据完整性和实时读写,这明显很难做到。
Kappa架构的实时数仓道路将何去何从?
4 新一代实时数仓
我们明白,Kafka的定位是消息队列,可作为热点数据的缓存介质,对于数据查询和存储其实并不适合。
4.1 数据湖技术
近些年,随着数据湖技术的兴起,仿佛看到了一丝希望。

目前市场上最流行的数据湖为三种: Delta、Apache Hudi和Apache Iceberg。
其中Delta和Apache Hudi对于多数计算引擎的支持度不够,特别是Delta完全是由Spark衍生而来,不支持Flink。
对于Iceberg,Flink是完全实现了对接机制。看看其具备的功能:
- 基于
快照的读写分离和回溯
流批统一的写入和读取
- 非强制绑定计算引擎
- 支持
ACID语义
- 支持表、分区的
变更特性
4.2 kappa架构升级
因此考虑对Kappa架构进行升级,使用Flink + Iceberg技术架构,可以解决Kappa架构中的一些问题。
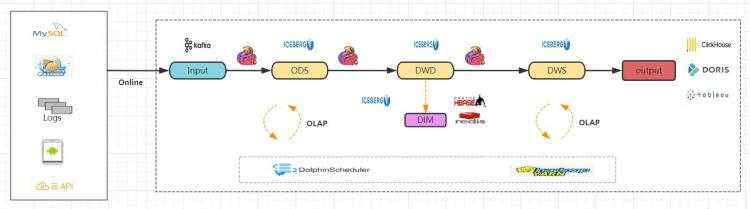
- 存储介质由Kafka换成Iceberg,其余技术栈保持不变
- Flink读取源头Kafka数据,结果存储到Iceberg ods层
- 继续执行后续的ods->dwd->dws层计算、结果存储
- Iceberg支持流批一体查询,过程中支持olap查询
- 实时olap引擎查询分析、报表展示
目前Flink社区关于Iceberg的建设已经逐渐成熟,其中很多大厂开始基于Flink + Iceberg打造企业级实时数仓。
有兴趣的小伙伴欢迎添加我的个人微信: youlong525一起讨论~
》》》更多好文,欢迎关注公众号: 大数据兵工厂










 京公网安备 11010802041100号
京公网安备 11010802041100号